
Fragmented data is the silent killer of enterprise AI initiatives. A disproportionate number of Generative AI (GenAI) projects stall or fail entirely. This is not due to algorithmic limits. Instead, it is because their underlying data infrastructure cannot support modern Large Language Models (LLMs).
The prevailing misconception is that AI data preparation is just an extension of existing analytics. In reality, preparing data for GenAI is a highly specialised manufacturing process. It demands specific technical maturity and formal governance to succeed.
When a foundational data environment is treated as low-priority debt, the organisation faces significant risks. These include model hallucinations, regulatory penalties, and a rapid erosion of trust.
This article provides a definitive, actionable framework to shift data readiness from an abstract concept into an operational capability. By focusing on four strategic pillars, organisations can systematically audit their current state. This establishes a robust, reliable data foundation necessary for sustainable GenAI success.
1. The Four Pillars of AI Data Readiness
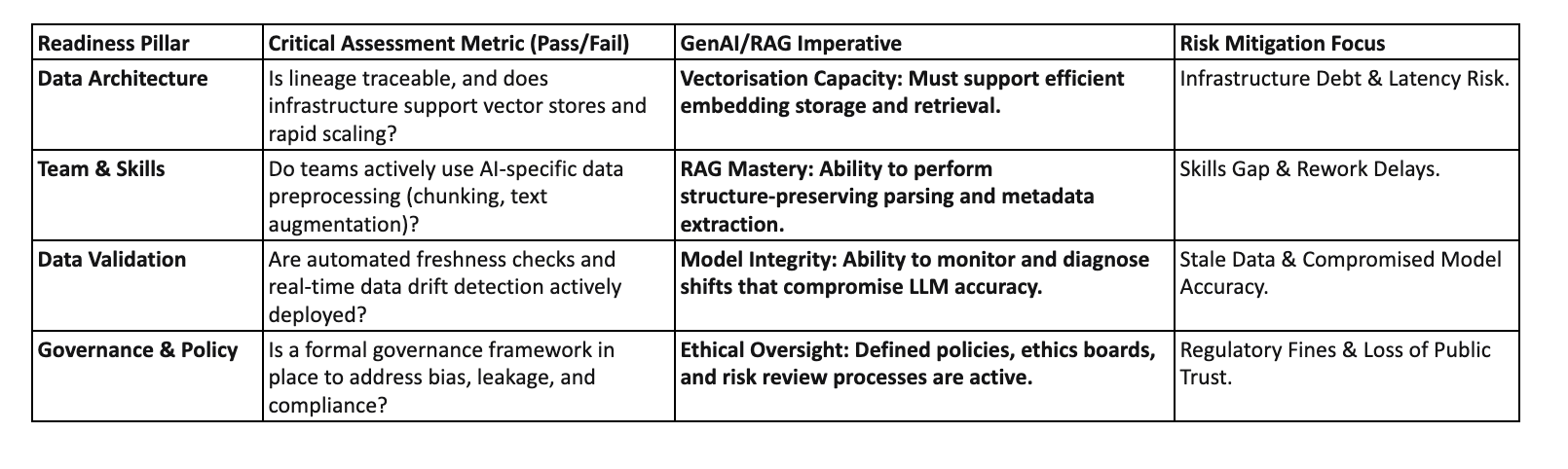
Successful AI implementation requires moving beyond traditional Business Intelligence (BI) metrics. It must address specialised architectural, team, validation, and governance requirements unique to GenAI workloads.
Pillar 1: Re-architecting for Speed and Context (Data Architecture)
Data architecture must demonstrate capabilities far exceeding those required for basic reporting. The assessment requires confirmation that current data sources are not only centralised, but that they also offer clearly traceable lineage.
The critical measure of AI readiness here is vectorisation capacity and rapid retrieval. The infrastructure must support vector stores and rapid retrieval mechanisms required for Retrieval-Augmented Generation (RAG) systems. If the infrastructure struggles to accommodate new data sources, it is not AI-ready. Data lineage is crucial for effective troubleshooting when an LLM produces unexpected results.
Pillar 2: Upskilling the Data Factory (Team & Technical Maturity)
The team’s operational maturity must be evaluated based on expertise in AI-specific data manipulation. It is insufficient for teams to only possess skills necessary for general reporting.
The essential question centres on whether teams have clearly defined skills in AI data preparation techniques. These include text augmentation, data chunking, and generating embeddings. This shift represents a substantial skills gap in many enterprises.
Effective AI data teams must implement or plan for AI-specific preprocessing to manage high costs and latency. This includes mastering techniques like instruction-tuning. This fine-tunes pretrained LLMs to follow specific task instructions, such as summarisation, ensuring greater accuracy. Operational maturity also demands robust governance frameworks, version control, and clear DevOps practices.
Pillar 3: Continuous Qualification and Trust (Data Validation Practices)
AI models are exquisitely sensitive to shifts in underlying data quality. Therefore, data validation must be a continuous, automated process, not an intermittent project.
The key capability in the GenAI environment is the ability to detect data drift or unexpected data changes in real time. Data drift represents a gradual, often undetected shift in data characteristics (analogous to the slow loss of tyre pressure). If this capability is absent, subtle shifts may compromise LLM accuracy without warning. Automated freshness checks and regression analysis must be part of the daily workflow.
Pillar 4: Formalising Responsibility and Ethics (Organisational Roles and Accountability)
Organisational readiness centres on clear accountability and the commitment to formal governance. Lack of clearly designated ownership for data infrastructure creates confusion and slowdowns.
The assessment must determine if the governance structure is formal. This involves a cross-functional governance group that regularly manages data definitions and metadata. This governance must explicitly address the risks unique to LLMs. This includes the mitigation of biases inherited from training data sets and the establishment of safeguards against legal and ethical risks. Establishing an AI ethics board is vital for ensuring alignment with ethical standards and societal values.
2. Deep Dive: Specialised Data Preparation for LLMs and RAG
The primary hurdle in GenAI adoption is the handling of unstructured data. This knowledge constitutes the majority of enterprise information. The challenge is translating complex document formats into usable context for LLMs.
The Unstructured Data Challenge
Naïve data parsing often fails when processing documents that contain integrated tables, diagrams, or images. These non-textual elements hold key information, and if they are glossed over, the LLM loses critical context. This leads to inaccurate responses.
The solution mandates three key activities during RAG data preparation:
- Structure-Preserving Parsing: This essential technique maintains the internal context and relationships within a document. Without it, tables are flattened into unintelligible text, leading to misinterpretation by the LLM.
- Chunking Strategy: Documents must be broken down into meaningful, retrievable blocks of context, known as chunks. The size and boundaries of these chunks are critical to retrieval accuracy.
- Metadata Extraction: Preserving file metadata (e.g., author, date, source) during the initial ingestion is critical. Metadata filtering allows RAG systems to retrieve relevant information based on classification, significantly improving the quality of generated responses.
The RAG Risk Profile: Data Leakage, Bias, and Hallucinations
GenAI systems introduce specific post-deployment risks that must be managed by the governance framework:
- Hallucinations: The model output contains inaccurate or nonfactual information. Proper grounding techniques, supported by quality RAG data, are the primary defence.
- Biases: LLMs can inherit biases from their massive pre-trained models. Active bias mitigation techniques and formal governance review are required to prevent embedding harmful decisions into operational systems.
- Data Leakage: If open data sets are used for fine-tuning, there is a risk that data already used in the base model’s training may appear. This can lead to overly optimistic performance during validation. This requires careful selection of pretrained models that provide transparency on their training data.
3. AI Data Readiness Assessment Matrix (Operational Blueprint)
The table below summarises the four pillars. It translates them into actionable operational requirements and links them to high-stakes risks, facilitating immediate executive decision-making.
Conclusion and High-Impact Next Steps
The evidence is unambiguous: achieving AI success is fundamentally dependent on mastering data readiness. Organisations that treat their data environment as merely a source of reports, rather than a specialised factory for AI context, will find their GenAI aspirations perpetually stalled or riddled with unacceptable risk.
Foundational data hygiene and a modernised, GenAI-focused data architecture are the greatest accelerators—or blockers—to a sustainable competitive advantage.
The four pillars—Architecture, Team, Validation, and Governance—provide the necessary roadmap to operationalise this capability. By moving toward a formal governance structure and upskilling teams in contextual preparation techniques, the enterprise transforms AI from a liability into a reliable, trustworthy strategic asset.
Now that the strategic blueprint has been defined, the imperative is immediate action. Delaying the audit of current data capabilities exponentially increases the operational and ethical exposure of the enterprise.
To begin the transition from abstract readiness to concrete action, utilise the core deliverable of this analysis:
Download the AI Data Readiness Assessment Matrix today. Stop guessing where your gaps lie and start building reliable, governed GenAI applications.